
Scaling your data is a critical step in the Machine Learning pipeline. It ensures that features contribute equally to the model and improves performance for algorithms sensitive to feature magnitudes.
In this tutorial on The Coding College, we’ll explain what scaling is, why it’s essential, and how to implement it in Python.
What Is Scaling in Machine Learning?
Scaling refers to transforming your data so that each feature has comparable ranges or distributions. Common methods include Standardization and Normalization.
Types of Scaling
- Standardization: Centers features around zero and scales to unit variance.
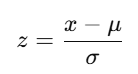
- Where:
- x: Original value.
- μ\mu: Mean of the feature.
- σ: Standard deviation of the feature.
- Normalization: Scales features to a fixed range, often [0, 1].
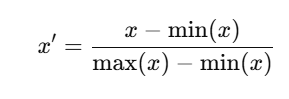
Why Is Scaling Important?
- Algorithm Sensitivity:
Some algorithms, such as SVM and KNN, rely on distance metrics. Large feature ranges can dominate these calculations. - Optimization Stability:
Gradient-based methods like Gradient Descent converge faster when features are scaled. - Improved Accuracy:
Ensures that all features contribute equally to the model.
When to Scale Your Data
- Before Training Models: Especially for distance-based or gradient-based algorithms.
- For Features with Different Units: Example: Height in meters vs. weight in kilograms.
Implementing Scaling in Python
1. Standardization Using Scikit-Learn
from sklearn.preprocessing import StandardScaler
import pandas as pd
# Sample dataset
data = {
"Height (m)": [1.5, 1.7, 1.6, 1.8, 1.75],
"Weight (kg)": [65, 70, 68, 80, 77],
}
df = pd.DataFrame(data)
# Initialize the scaler
scaler = StandardScaler()
# Apply scaling
scaled_data = scaler.fit_transform(df)
# Convert back to DataFrame
scaled_df = pd.DataFrame(scaled_data, columns=df.columns)
print(scaled_df)2. Normalization Using Scikit-Learn
from sklearn.preprocessing import MinMaxScaler
# Initialize the scaler
min_max_scaler = MinMaxScaler()
# Apply normalization
normalized_data = min_max_scaler.fit_transform(df)
# Convert back to DataFrame
normalized_df = pd.DataFrame(normalized_data, columns=df.columns)
print(normalized_df)3. Manual Scaling
For smaller datasets, you can manually scale data using NumPy:
import numpy as np
# Standardization
def standardize(column):
return (column - np.mean(column)) / np.std(column)
# Normalization
def normalize(column):
return (column - np.min(column)) / (np.max(column) - np.min(column)
df["Height (Standardized)"] = standardize(df["Height (m)"])
df["Weight (Normalized)"] = normalize(df["Weight (kg)"])
print(df)Visualizing the Effect of Scaling
import matplotlib.pyplot as plt
# Original data
plt.scatter(df["Height (m)"], df["Weight (kg)"], color="blue", label="Original")
# Scaled data
plt.scatter(scaled_df["Height (m)"], scaled_df["Weight (kg)"], color="red", label="Scaled")
plt.title("Effect of Scaling")
plt.xlabel("Height")
plt.ylabel("Weight")
plt.legend()
plt.show()Exercises
Exercise 1: Scaling a Dataset
Load a dataset (e.g., from Scikit-Learn’s datasets) and scale it using both StandardScaler and MinMaxScaler. Compare the results.
Exercise 2: Impact of Scaling on Algorithms
Train a K-Nearest Neighbors (KNN) classifier on scaled and unscaled data. Compare accuracy.
Key Takeaways
- Scaling is essential for ensuring that all features contribute equally to the model.
- Use Standardization for algorithms that assume normally distributed data.
- Use Normalization for bounded data or when feature ranges vary widely.
By scaling your data effectively, you’ll set up your Machine Learning models for success.
Why Choose The Coding College?
At The Coding College, we prioritize teaching practical and actionable Machine Learning techniques like Scaling. Join us to enhance your data science journey.